Improve DBT Incremental Performance on Snowflake using Custom Incremental Strategy
Dec 19, 2025
Data

The following presents how to improve the performance of the DBT built-in delete-insert incremental strategy on snowflake so we can control snowflake query costs. It is broken down into:
Defining the problem, with supporting performance statistics
Desired solution requirements
Solution implementation, with supporting performance statistics
TL;DR
We implemented a DBT custom incremental strategy, along with incremental predicates to improve snowflake query performance:
Reduced MBs scanned by ~99.68%
Reduced micro-partitions scanned by ~99.53%
Reduced query time from
19seconds to1.3seconds
Less data is being scanned, so the snowflake warehouse is waiting less time on I/O, so the query completes faster.
Disclaimer
Custom incremental strategies and incremental predicates are more advanced uses of DBT for incremental processing. But I suppose that’s where you have the most fun, so lets get stuck in!
Problem
When using the DBT built-in delete-insert incremental strategy on large volumes of data, you can get inefficient queries on snowflake when the delete statement is executed. This means queries take longer and increase warehouse costs.
Taking an example target table:
With
~458 millionrowsIs
~26 GBin sizeHas
~2560micro-partitions
With a DBT model that:
Is running every
30 minutesTypically there are
~100Krows to merge into the target table on every run. As data can arrive out-of-order, a subsequent run will pick these up, but means it can include rows already processed.
With DBT model config:
Default delete SQL generated by DBT, before it inserts data in the same transaction:
Performance Statistics
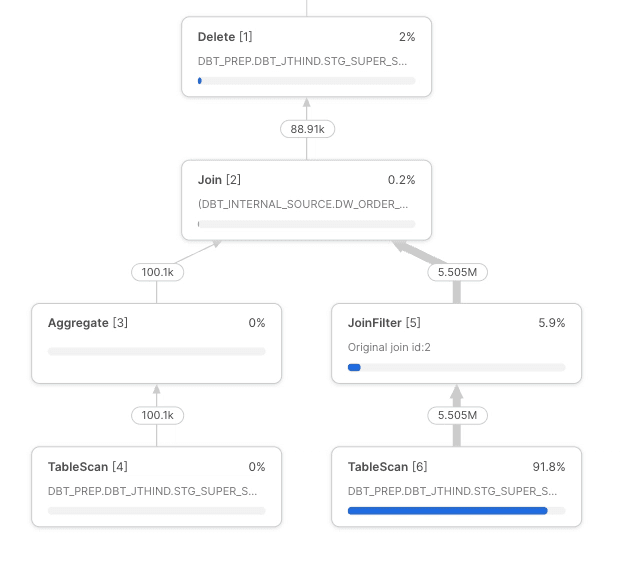
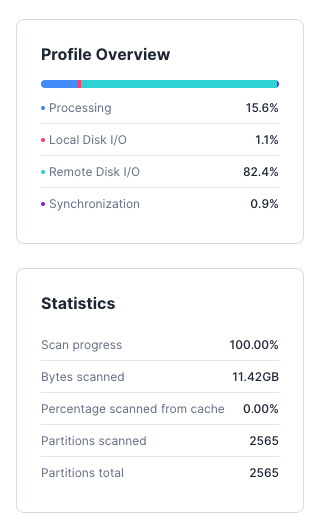
To find the rows in the target table to delete with the matching dw_order_created_skey (see node profile overview image below), snowflake has to:
Scan
~11 GBof the target tableScan all
~2560 micro-partitionsQuery takes
~19 seconds
Why? - The query is not filtering on order_created_at to allow snowflake to use the clustering key of to_date(order_created_at) to find the matching rows to delete.
Query plan
Desired Solution
To limit the data read in the target table above. We can make use of incremental_predicates in the model config. This will add SQL to filter the target table.
DBT model config:
Issues with this
The incremental_predicates docs states dbt does not check the syntax of the SQL statements, so it does not change anything in the SQL.
We get an error when it executes on snowflake:
Object 'DBT_INTERNAL_SOURCE' does not exist or not authorized.We cannot hardcode the snowflake table name in the incremental_predicates, as its dynamically generated by DBT.
Solution Implementation
We need to:
Do some pre-processing on each element of
incremental_predicatesto replaceDBT_INTERNAL_SOURCEwith actualsource_temp_tableso SQL like the below is generated by DBT for better performance:
Continue to call the default DBT
delete+insertincremental strategy with the new value forincremental_predicatesin the arguments dictionary.
How - The below macro implements a light-weight custom incremental strategy do this. You can see at the end it calls the default get_incremental_delete_insert_sql DBT code.
This is now callable from the DBT model config by setting incremental_strategy to custom_delete_insert.
Performance Improvement Statistics
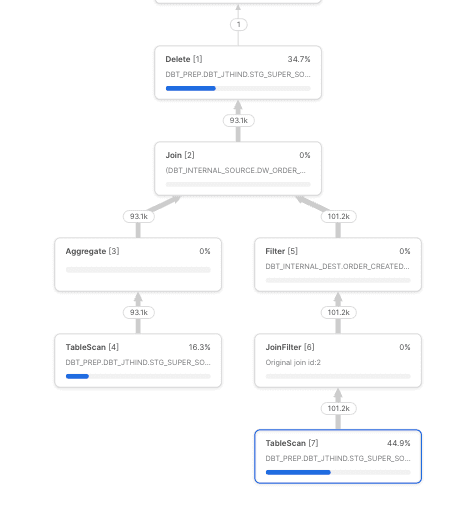
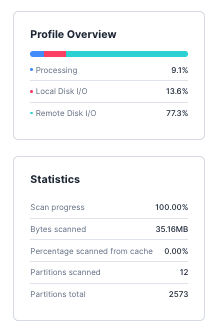
To find ~100K rows to delete in the target table, now snowflake has to only:
Scan
~35 MBof the target table, 11 GB → 35 MB = ~99.68% improvementScan
12 micro-partitions, 2560 → 12 = ~99.53% improvementQuery takes
~1.3 seconds
Less data is being scanned, so the snowflake warehouse is waiting less time on I/O, so the query completes faster.
Query plan
If you're interested in hearing more about how we use DBT at Super Payments, feel free to reach out!
Jag Thind, Data















June 30, 2025
Super Thinking
